Search algorithms
By Afshine Amidi and Shervine Amidi
Basic search
Linear search
Linear search is a basic search method often used when the relative ordering of elements is not known, e.g. in unsorted arrays. It has a complexity of time and space:
Scan step: Check whether the constraint of the problem is verified on the first element of the array.

Repeat the process on the remaining elements in a sequential way.

Final step: Stop the search when the desired condition is satisfied.

Two-pointer technique
The two-pointer technique provides an efficient way to scan arrays by leveraging the assumptions of the problem, e.g. the fact that an array is sorted.
To illustrate this concept, suppose a sorted array. Given , the goal is to find two elements such that .

The two-pointer technique finds an answer in time:
Initialization: Initialize pointers and that are set to be the first and last element of the array respectively.

Compute step: Compute .
Case : The computed sum needs to increase, so we move the pointer to the right.

Case : The computed sum needs to decrease, so we move the pointer to the left.

Final step: Repeat the compute step until one of the following situations happens:
Case : There is no solution to the problem.

Case : A solution is found with and .

Trapping rain water
A classic problem that uses the two-pointer technique is the trapping rain water problem. Given a histogram that represents the height of each building , the goal is to find the total volume of water that can be trapped between the buildings.

Tricks
The maximum volume of water trapped at index is determined by the relative height between and the tallest buildings on the left and on the right :
Use the two-pointer technique to efficiently update and at each step.

The solution is found in time and space:
Initialization:
Pointers: Set the left and right pointers to and .
Maximum heights: Set the maximum height of the left buildings and the right buildings to and .
Total amount of water: Set the total amount of water to 0.
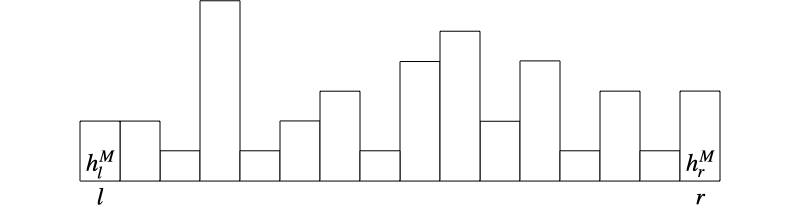
Compute step: Update the values of the maximum heights of left and right buildings with the current values:
If , then the left side is the limiting side, so:
Add the available volume at index to the total amount of water :
Move the left pointer to the right:

Conversely, if , then:
Add the available volume at index to the total amount of water :
Move the right pointer to the left:

Final step: The algorithm finishes when the two pointers meet, in which case the amount of water is given by .

Binary search
Algorithm
Binary search aims at finding a given target value in a sorted array .
This algorithm has a complexity of time and space:
Initialization: Choose the lower bound and the upper bound corresponding to the desired search space. Here, and .

Compute step: Compute the middle of the two bounds:
The above formula is written in a way that avoids integer overflow in case and are too large.

We have the following cases:
Case : Shrink the search space to the left side by updating to .

Case : Shrink the search space to the right side by updating to .

Case : We found a solution.

Final step: Repeat the compute step until one of the following situations happens:
Case : A solution is found.
Case : There is no solution since the pointers intersect after fully covering the search space.
Median of sorted arrays
Suppose we want to compute the median of two sorted arrays of respective lengths , with .

A naive approach would combine the two sorted arrays in time, and then select the median of the resulting array. However, a approach exists that uses binary search in a clever way.
Tricks
If we categorize all elements of both arrays into:
A left partition that has the smallest elements.
A right partition that has the biggest elements.
Then we can deduce the median by looking at the maximum of the left partition and the minimum of the right partition.
If we know how many elements from are in the left partition, then we can deduce how many elements from are in there too.

By noting the left and right partitions from and , we know the partitioning is done correctly when the following conditions are satisfied:

The binary search solution is based on the position of the partitioning within the array . The solution is found in time:
Initialization: We note and the lengths of the left partitions within array and respectively. We fix the total size of the left partitions to be .

For a given , the following formula determines :
Binary search: We perform a binary search on between and .
For each candidate, we have the following cases:
(C1) is not satisfied: We restrict the search space to the left side of .

(C2) is not satisfied: We restrict the search space to the right side of .

Both (C1) and (C2) are satisfied: The partitioning is done correctly.

Final result: Once the correct partitioning is found, we deduce the value of the median. We note:
We have:
| Case | Result | Illustration |
|---|---|---|
| even |  | |
| odd |  |
Substring search
String pattern matching
Given a string of length and a pattern of length , the string matching problem is about finding whether pattern appears in string .

We note the substring of of length that starts from and finishes at .
Brute-force approach
The brute-force approach consists of checking whether pattern matches any possible substring of of size in time and space.
Starting from , compare the substring that starts from index with pattern .

We have the following possible situations:
One of the characters is not matching: The pattern does not match the associated substring.

All characters are matching: The pattern is found in the string.

Knuth-Morris-Pratt algorithm
The Knuth-Morris-Pratt (KMP) algorithm is a string pattern matching algorithm that has a complexity of time and space.
Intuition Avoid starting the pattern search from scratch after a failed match.


We do so by checking whether the pattern matched so far has a prefix that is also a suffix:
Step 1: Build the prefix-suffix array.

Step 2: Find the pattern in the original string using the prefix-suffix array.

Prefix-suffix array construction We want to build an array where each value has two interpretations:
It is the length of the largest prefix that is also a suffix in the substring .

It is also the index in the pattern that is right after the prefix.

This part has a complexity of time and space:
Initialization:
By convention, we set to .
The element is set to 0 since the substring has a single character.
The pointers and find the largest prefix that is also a suffix to deduce the value of . They are initially set to and .

Compute step: Determine the length of the largest prefix that is also a suffix for substring :
Case and : The substring does not have a prefix that is also a suffix, so we set to 0:
We increment by 1.

Case : The last letter of the substring matches with . As a result, the length of the prefix is the length of :
We increment both and by 1 respectively.

Case and : The substring may have a smaller prefix that is also a suffix:
We repeat this process until we fall in one of the two previous cases.

Linear-time string pattern search We want to efficiently search pattern in string using the newly-constructed prefix-suffix array .
This part has a complexity of time and space:
- Initialization: The pointers and check whether there is a match between each character of the string and the pattern respectively. They are initially set to 0.

Compute step: We check whether characters and match.
Case : The characters match. We increment and by 1.

Case : The characters do not match. We determine where we should start our search again by using the information contained in the prefix-suffix array.
: We need to restart the pattern match from the beginning since there is no prefix/suffix to leverage.
: We can continue our search after the next largest matched prefix of the pattern.
We set to .

Final step: The algorithm stops when one of the following situations happens:
Case : The pattern has been matched.
Case and : The whole string has been searched without finding a match.

Rabin-Karp algorithm
The Rabin-Karp algorithm is a string pattern matching algorithm that uses a hashing trick. It has an expected time complexity of , but depending on the quality of the hash function, the complexity may increase up to . The space complexity is .
Intuition Compute the hash value of the pattern along with those of the substrings of the same length. If the hash values are equal, confirm whether the underlying strings indeed match.
The trick is to choose a hash function that can deduce from the hash value of the previous substring in time via a known function :

Algorithm
Initialization: Given a hash function , we compute the hash value of the pattern .

Compute step: Starting from index , we use the hashing trick to compute the hash value of substring that starts from and that has the same length as in time.
Case : and definitely do not match.

Case : There may be a match between and , so we compare and .
Sub-case : The pattern has been matched.
Sub-case : There is a collision between the hash values of and . Since there is no match, we continue the search.

Subscribe here to be notified of new Super Study Guide releases!